Modeling Audience Group Behavior

This page describes a project by
Nuria
Oliver
and
Stephen Intille for
the MIT Media Lab Spring
1996 class
Modeling Autonomous Agents.
The Goal
The goal of this project is to implement a system that can model
audience behavior using multiple, communicating agents. Each agent
is a simple model of a person sitting in a grid-like auditorium. The
person can listen for different types of stimuli such as clapping and
whistling coming from nearby audience members. Each audience agent
then has instructions on how to respond to what it observes. For example,
some agents may be given instructions to
"Clap in sync with the
people who are clapping."
Another group of agents may be given the
instructions: "Whistle for a second every 4 claps you hear". And so on.
There can be several different types of audience agents, each with
different types of behaviors. The idea is to try and construct
audience simulations that start off with chaotic/random behavior and
eventually converge to some interesting "collaborative" behavior like
a special rhythm or a visual display. The higher level structure emerges
from the individual behaviors, in a completely
decentralized
way.
Agents neither do have a particular language nor explicitly
communicate among each other. Communication is performed
through
the environment
by paying attention at each instant of time
to how other agents are acting
and have acted in the recent past.
The inspiration for this project came about after a class brainstorming
session on ways that a speaker at a graduation with several thousand people
could do some type of interactive task with an audience. A model that works
successfully in our system could be tested with a real crowd by taping
small slips of papers to auditorium chairs before the arrival of the crowd
and then surprising the crowd during a talk by asking them to reach under
their chair, get their instruction, and perform the action described. With
a bit of luck, chaos would gradually turn to collaborative behavior.
This document describes our current system, the tests we have performed,
and the issues that it raises.
Each audience simulation can use up to ten different types of agents.
The agent types are defined by the user by setting four parameters:
- Action Type
-
Each agent has a type of action that it can perform. Currently the
actions are either clap, whistle, or do nothing. New actions can be easily
added, such as display a card of a certain color. Agents are limited to doing a single type of action.
- Listen Type
-
Each agent can perceive
one or more types of behavior. For example, some agents might listen for clapping
whereas other agents might listen for whistling and
clapping. The resulting agent behavior depends on the type of
behaviors it is listening to.
- Desired Frequency
-
An agent has a goal of performing its designated action at a
certain frequency relative to the frequency of its neighbors whose
type of behavior coincides with the behaviors the agent is able to perceive.
For instance, one can define an agent that whistles every four
claps it perceives. The details of how the agent perceives a clap
as well as how it determines its sync frequency with respect to
the group are discussed later.
- Connection Type
-
All agents can "listen" to a grid of agents centered around
each agent's position. The size of this grid can be interactively changed by
the user. For example, if the user sets a grid size of 1 x 1,
a grid with one seat in front behind, left, and right is
attended to (in other words an 8-connected region). A grid of
size 2 x 2 would mean an agent listens to 24 agents (25 minus the agent
itself). Clearly, such a simple listening strategy does not accurately
model real perception in an auditorium-type of situation. Audience members
can attend to stimuli from many more people than those immediately next to
them, including people making noise who may be hundreds of seats
away. Moreover, the people who are listened to are probably not uniformly
distributed.
In addition to distance, factors like tone and loudness determine
whether a person is attended to or not.
The
computational load of modeling each agent listening to hundreds of other
agents prevented us from implementing such models. However, we think even
local neighborhoods should be useful for studying audience behaviors.
If the user is willing to wait, though, a very large listening
neighborhood can be set.
For each type of agent, the user also sets one two variables:
- Percentage
-
This number indicates the percentage of the audience of the
given type. For example, in a simulation with three
agents, the audience can be set to be 30% of agent type 1, 20%
of agent type 2, and 50% agent type 3. The agents will be
randomly distributed in the seating grid.
- Color
-
Each type of agent has a different color which is shown every time this
agent is acting at the agent's grid location. The color is
selected interactively by the user.
The System
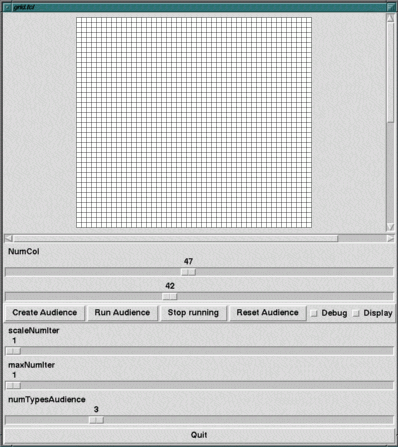
The images below show two screen shots. The first is the main user
interface. The user can adjust the size of the seating grid, the number of
agent types, and the maximum number of iterations. It is possible to
turn the display on and off so that a very large number of iterations
can be run quickly. The Tcl/Tk interface is reasonably fast. However, displaying
a grid with hundreds of agents might take around one second.
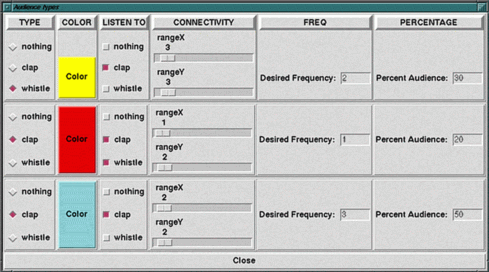
Once the number of agent types is set, an additional window allows the user to
specify the agent characteristics for each
time. Among them, the
percentage of the audience of each type or the color
for each agent type. Up to ten agent types can be
created. After introducing all the features for each type of agent, a
new audience can be created by pressing the Create Audience button.
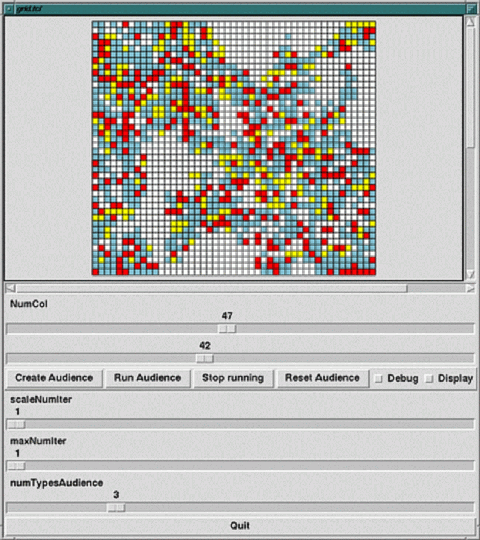
Once the audience has been created, a new simulation of its behavior
can be run. In order to do that, the user needs to hit
Run
Audience
. Then, the public
agents start performing their behaviors. Their activity is represented
by the user selected colors in the audience grid. Whenever an agent is
acting, i.e. is performing its specific behavior, its seat will flash
with the agent's color. For instance, A clap action with a
desired frequency of 2 might be represented by a "red seat" lighting
up in the grid on the clock tick when an audience member performs the clap.
The following image is a screen shot of the audience grid at one random
clock tick during a run.
The simulation continues to run until it reaches the desired number
of iterations. When the display is deactivated, a grid with several
hundred seats can be run for several hundred iterations in just a few
seconds with an 8-connected listen-to grid.
Temporal Perception
One tricky aspect of the simulation is modeling temporal behavior.
If
several agents that one agent listens to all acted in the
last second at different times, what time is used by the agent to decide
when it should perform it's own action?
It needs to do some type of simple
frequency detection.
For instance, an agent who is supposed to whistle every 2 claps needs
to listen to other agents and try to detect their clapping frequency. Since
it may hear many non-synchronized claps within a short time period
(particularly at the start of the simulation before behavior has
converged), it needs a method for determining a frequency of clapping
given what it heard.
It seems obvious that agents need memory in order to be able to
infer from the environment their neighbors frequency. In our simulation, each agent stores a memory of what it has done
over the last sixteen time steps (the memory length of the
agents is a parameter of the program). Other agents -those whose
neighborhoods include the particular agent- can then access that
representation, thereby knowing what neighbors did in the last
sixteen time steps. Agents use the temporal information of neighbors to
compute their own action frequencies.
The method currently in use works as follows:
-
-
The agent looks at the
temporal history of its neighbors. Assume the agent is listening for
"claps." For each of the last sixteen time steps, it sums up the number of
claps made by neighbors during each clock tick. In order to compute
its neighbors frequency, it looks for the two
time steps with the most claps and declares the "clapping frequency" to be
the amount of time between these two times. Therefore a
majority rule is applied when determining this frequency. In
fact, this rule seems to be what we humans do when trying to determine
a global behavior of a group. It then decides when it needs
to clap next to satisfy it's goal. If the agent can't find two time steps
that have more claps than the rest, it randomly decides when to clap
next. Other more complex types of frequency detection strategies could be implemented.
The situation is actually a bit more complicated than this, because
some agents listen to two types of behavior: their own and another type.
If an agent is supposed to whistle every three claps, it is possible to
have that group of agents all whistling every three claps, but not all
whistling together. If the agent is supposed to also listen to
whistling, the desired behavior is that each agent whistles every three
claps and they all whistle together.
Audience Simulations
We ran a number of different audience simulations. General trends that
summarize them are
described below. We found the the system performs as we expected it
would and consequently it seems to be an adequate initial model of
this type of audience behavior.
- Two groups, not inter-related
-
-
When two groups of agents are run that do not listen to each other
(for instance,
a clap group listening only to a clap group and a
whistle group only listening to a
whistle group
), they each converge rapidly within group but the two
groups don't converge with each other, given that they are
absolutely independent. In this case, the environment is only used a a
communication media within each of the groups.
-
Two groups, inter-related, same frequency
-
-
An example of this case is
clap listens to whistle, whistle listens
to clap, both with a frequency of one
. This simulation will rapidly
converge so that everyone is acting simultaneously.
-
Two groups, inter-related, different frequency
-
-
This example will either converge or diverge, depending upon
who is listening to what. An illustration of convergence is
a case in which
clap listens to clap and whistle
listens to clap, with frequencies of one and two
respectively
. In this case,
the clapping group will synchronize their clapping and the
whistling group will whistle
every two claps. However, if the test run is clap listens to clap and
whistle and whistle listens to clap, the clappers can never converge
because the whistlers are trying to synchronize to the clappers
who are, in turn,
trying to synchronize to the whistlers and so on.
Audience parameters and behavior analysis
-
Neighborhood size and speed
-
-
The size of the neighborhood that agents listen to affects the
speed
of convergence
. The larger the neighborhood, the faster the
convergence. Since real people in an auditorium have very large
neighborhoods, convergence would probably be very fast in most
cases. (This is what happens when a group of people in a room
are all asked to synchronize clapping. It only takes a second
or so before everyone is together).
-
Neighborhood size and convergence
-
-
The size of the neighborhood can also affect the
convergence of the audience to the synchronized desired behavior.
It is possible to set the ratio of agent types so that the agents
that are in the minority need to listen to a larger area in order
to hear anything. The result is that the agents will not converge
with a small listen grid but will converge with a larger listen
grid.
-
Agents distribution and percentages
-
-
The percentages of each type of group affect the percentage
of the agents that end up with converged behavior. If there is
a high percentage of agents that can converge (e.g. clap listens
to clap) and a low percentage of agents that cannot (e.g. whistle
listens to clap and whistle with frequency 2) the whole system
won't converge but large subregions will, because the non-converging
agents are very spread out. The global audience behavior consists
of a clustering of synchronized group behaviors
-
Isolated agents
-
-
The system is designed so that completely isolated agents who
happen to have
no agents in their listening area of a type they listen to do
nothing. This quiet behavior is reflected in the interface
by white seats that never flash.
-
General behavior
-
-
In general, the behavior of a non-convergent system
consists of a clustering of agents in different groups
that converge, while agents on the boundaries of subgroups
oscillate, trying to satisfy the requirements of the two
non-convergent groups. The
size of the clusters depend upon the neighborhood size.
Problems/Issues
-
Ideally, the algorithm should allow behavior to change over time,
because the convergence process can be broken into two parts: before
convergence and near convergence. We discovered that there is
some temporal behavior we would like agents to have only after
the system has converged somewhat because if this particular behavior is
implemented from the start, the entire convergence process is
jeopardized. Initially all the behaviors are set randomly and,
until the histories of each agent are long enough, the system should
be flexible enough to allow this essentially random behavior. On the
other hand, once the memory of each agent is filled with useful
information about its neighbors, it should start acting less randomly
and pay more attention to how its neighbors are behaving. This
two-fold agent reaction to what it is happening in its surroundings
reflects how a real audience synchronizes itself over time: initially
each person starts clapping, for instance, with his/her own
frequency. After some initialization time, he/she starts synchronizing
his/her frequency to what is able to perceive, i.e. to the global audience
apparent frequency.
-
Handling temporal information is always tricky. The major problem is
that an agent needs to look at the temporal history of its neighbors
and use a policy to decide when to act next. This needs be done
with special attention
because if the agent is not careful enough it can end changing its
elapsed
time to
act at every timestep so that it never acts!
-
Since the agents are so strongly interdependent,
policy changes intended to fix a problem with one
agent situation end up spreading to a large number of agents and
affecting the entire audience. Even though this effect of
small changes spreading through the environment is the primary
motivation behind designing a system with
emergent behavior, the design, practical
implementation, and debugging of such an architecture is tricky and
somewhat counter-intuitive.
Conclusions and Possible Extensions
Some possible extensions are:
-
Use more realistic models of audience member perception. Our current
system uses a variable size grid centered on each agent, but in reality
a person in an
audience can hear people who are many seats away, in addition to
a few loudmouths who may be all the way across a large auditorium.
-
Include real audio output to the system
instead of representing sounds with colors. In this way,
musical as well as color behaviors would result.
-
Explore different temporal frequency
determination policies. Our current seems to work well (minus a small
bug
we have been unable to exterminate), but other policies might
result in faster and better convergence.
-
The Tcl/Tk display code is too slow on large grids. Using X for display would make
the system run faster when displaying the system states. Since
the display can be turned off during a run, this is a minor
issue.
-
The algorithm for randomly distributing the agents with the
specified percentages, tends to concentrate at the last area of the grid
agents of the minority group, i.e., of the group with the smallest
percentage. This is due to the weighting policy we employed for
assigning agents to seats: the majority group happens to have a higher
probability of being distributed earlier (i.e. at the beginning of the
grid) than the minority group. However, this effect is minor and does no affect
algorithm
performance.
-
A parallel implementation would allow much larger and more realistic
simulations. Now if only we had a parallel computer ...
Finally, the ultimate and most interesting extension would be test a working model with a
real audience!
Technical Details
The code is written in C++ and Tcl/Tk and the current version has been
compiled on an SGI Indy workstation. A significant amount of time was
required to get the interface code running properly, given that new
Tcl/Tk commands have been added and implemented in C++. The code is available
by request to anyone who wants it, but is not
supported. If you'd like a copy or have any questions or feedback
about this project, contact
us. We will be happy to answer your questions,
and any type of constructive criticism is welcome.
Who Did What?
Modify the interface Grid code: Nuria
Add agent behavior code: Nuria and Stephen
Test runs: Nuria and Stephen
Video: Nuria and Stephen
Report/Web page: Stephen
Review of Report: Nuria and Stephen
Presentation: Nuria and Stephen
And Finally...
Nuria Oliver Ramirez
and
Stephen Intille
were graduate students at the Vision and Modeling Group
of the MIT Media Lab when they did this
project. In addition
to fun projects like this one, they also do research in
computer vision and perception understanding.
We'd appreciate any comments
that you may have on this work or on possible extensions.
Last modified: 5/21/96 by intille@media.mit.edu & nuria@microsoft.com.